Fujitsu Develops AI Reconstruction Technology for Lightweight, Energy-Efficient Takane LLM Models
Fujitsu has announced a new generative AI reconstruction technology for its Fujitsu Kozuchi AI service, enhancing the Takane LLM with lightweight, power-efficient AI models. The technology combines 1-bit quantization and specialized AI distillation, achieving a 94% reduction in memory consumption, an 89% accuracy retention rate compared to the unquantized model, and a three-fold increase in inference speed. This surpasses conventional quantization methods like GPTQ, which typically retain less than 20% accuracy.
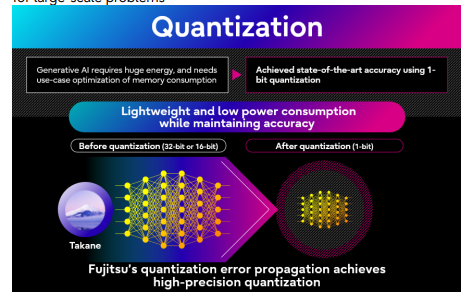
The quantization technology compresses AI model parameters, reducing size and power consumption while accelerating performance. A new algorithm addresses quantization error propagation across neural network layers, enabling 1-bit quantization. The specialized distillation process optimizes model structure by pruning unnecessary knowledge, adding transformer blocks, and using Neural Architecture Search (NAS) to select models balancing GPU resources, speed, and accuracy. Knowledge is transferred from teacher models like Takane, resulting in compressed models with enhanced task-specific accuracy.
Testing on a text QA task for sales negotiation prediction showed an 11-fold inference speed increase, 43% accuracy improvement, and 70% reduction in GPU memory and operationa...